
Consequently, an additional and independent condi tional method is needed. Recently, yet another inducible sys tem was produced that permits conditional protein degradation. The human FK506 and rapamycin binding protein is swiftly and constitutively degraded in mammalian cells. Protein fusion of its desta bilizing domain transfers the instability to any professional tein of curiosity. Addition of your synthetic ligand Shld1 that binds to your destabilizing domain protects the fusion protein from speedy degradation and consequently enhances abun dance of your protein of interest. An enzyme that acts absolutely independent of FLP and catalyses precise integration at high efficiency is definitely the serine integrase derived through the phage FC31. This FC31 integrase mediates web-site particular recombination involving two DNA sequences, the phage attachment web site, attP, as well as the bacterial attachment site, attB.
Impor tantly, recombining the attP and attB web-sites generates two hybrid websites, attL and attR, which cannot be acknowledged by the integrase and therefore in contrast to your FLP recombi nase, the response is unidirectional learn this here now and a great deal more productive. In a number of mammalian cell lines it has been proven that a plasmid containing the attB sequences inte grates with various efficiency into pseudo attP internet sites from the genomic DNA. You can find about a hundred distinct inte grations websites that demonstrate distinctive frequency of integration. Sequencing of those pseudo attP websites after integra tion showed that these recombinations weren’t comple tely precise in the sequence degree, differing slightly on the integration junction.
In contrast the integration into wild type attP sites inserted in to the mammalian genome was invariable precise leading to the expected recombi nation selleck occasion in the sequence degree. This home is most useful to layout tactics to define attP web-site particular integrations. Comparing within the human cell line HEK293 the integration frequency in between the pseudo attP websites and a wild style attP site, about 15% on the integrations occurred at the launched wild type attP website. In con trast, probably the most frequent pseudo attP internet site was used at 5% suggesting the wild form attP web site is preferred. To prevent undesirable integration at pseudo attP web sites a selection is needed for distinct integration at a pre exist ing attP docking website utilizing corresponding markers. This can finest be achieved by activation of an antibiotic resis tance gene on good recombination.
Considerably, the fusion of the nuclear localization signal towards the FC31 integrase has proven an eightfold increase while in the integrase activity suggesting that this really is an important modification to obtain optimal exercise in vertebrate cells. In this review, we mix the Shld1 inducible process with FC31 integrase mediated specific integration in the background in the tetracycline inducible FLP mediated process to get two wholly independent methods of transgene activation in one along with the similar cell.
Consequently, an additional and independent condi tional process
Reply
 diagnosed as RCC connected with Xp11. two translocation/TFE3 gene fusion. Renal vein involve ment was demonstrated, but lymph node metastasis and distant metastasis had been absent. Accordingly, the tumor was classified as pT2pN0M0, Stage II. Alpha interferon was administered as adjuvant treatment following the surgery.
diagnosed as RCC connected with Xp11. two translocation/TFE3 gene fusion. Renal vein involve ment was demonstrated, but lymph node metastasis and distant metastasis had been absent. Accordingly, the tumor was classified as pT2pN0M0, Stage II. Alpha interferon was administered as adjuvant treatment following the surgery.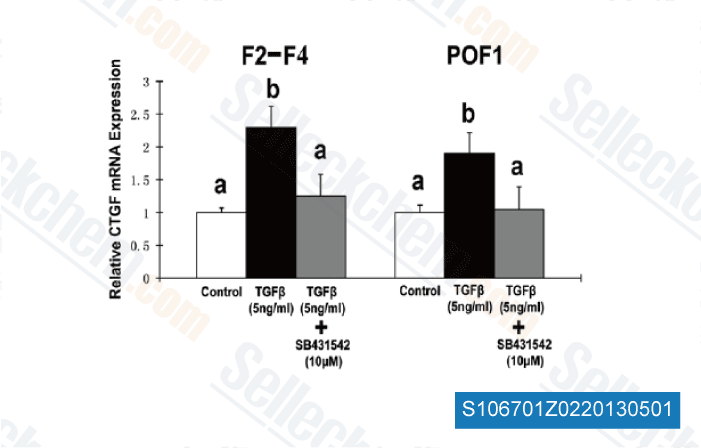 expres sion pattern uncovered within the qPCR analysis and the DGE benefits contain two ACC oxidase genes, a SIB1 like gene, a thaumatin PR5 like genes, an WRKY75 like gene, an acidic endochitinase gene, in addition to a gene encoding a homolog from the EIN3 binding F box protein one, Based mostly to the DGE result, the transcript encoding a homolog of the Arabidopsis WRKY40 was identified to get re duced by in excess of 10 folds at 3 hrs and 51 hrs post infection with Foc1 in contrast together with the mock inoculated samples.
expres sion pattern uncovered within the qPCR analysis and the DGE benefits contain two ACC oxidase genes, a SIB1 like gene, a thaumatin PR5 like genes, an WRKY75 like gene, an acidic endochitinase gene, in addition to a gene encoding a homolog from the EIN3 binding F box protein one, Based mostly to the DGE result, the transcript encoding a homolog of the Arabidopsis WRKY40 was identified to get re duced by in excess of 10 folds at 3 hrs and 51 hrs post infection with Foc1 in contrast together with the mock inoculated samples. transporter NRT2. 5 or NRT2.seven was abundant in tolerant genotypes in comparison to CK60. Other transcripts encoding nitrate transporters, NRT2. two, NRT2. three, and NRT2. 6 have been also abundant in China17 and KS78 compared to sensitive genotypes. Fd NADP reductase transcript was abundant in China17 when compared with sensitive genotypes, however the response was slight. Expression of a transcript encoding enzymes concerned in ammonia assimilation, glutamate synthetase was abundant in KS78 and large NUE bulk, but not in China17 and San Chi San relative to CK60. Conversely, glutamine synthetase transcript was abundant in CK60 when compared with tolerant genotypes.
transporter NRT2. 5 or NRT2.seven was abundant in tolerant genotypes in comparison to CK60. Other transcripts encoding nitrate transporters, NRT2. two, NRT2. three, and NRT2. 6 have been also abundant in China17 and KS78 compared to sensitive genotypes. Fd NADP reductase transcript was abundant in China17 when compared with sensitive genotypes, however the response was slight. Expression of a transcript encoding enzymes concerned in ammonia assimilation, glutamate synthetase was abundant in KS78 and large NUE bulk, but not in China17 and San Chi San relative to CK60. Conversely, glutamine synthetase transcript was abundant in CK60 when compared with tolerant genotypes.